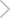1.91 k
1.91 k
作者:姚琦,腾讯 CSIG 工程师
本文介绍了如何在 Oceanus 平台使用 tdsql-subscribe-connector [1] ,从 TDSQL-MySQL 订阅任务 [2] 创建,到 Oceanus 作业创建、最终数据验证,实现全流程的操作指导。需要注意的是,本文默认已经创建 TDSQL-MySQL 实例和 Oceanus 集群,并且二者在同一 VPC 下或者不同 VPC 下但网络已经打通。

上述流程图简要说明了使用 tdsql-subscribe-connector 时,整个数据流向情况。TDSQL 的 binlog 数据,会通过订阅任务发送到 Kafka(这里的 Kafka 已经包含在订阅任务中,无需重新创建实例),然后 Oceanus 可以通过 tdsql-subscribe-connector 接入 Kafka 的数据,由于 Kafka 中的消息格式比较特殊,无法用常规 Kafka Connector 接入。
创建订阅任务
创建订阅任务可以参考 数据传输服务 TDSQL MySQL 数据订阅 [3] ,在订阅任务创建过程中,需要选择订阅的对象,可以选择不同数据库下的不同表,或者同一数据库下的不同表,当订阅多个表的 binlog 时,多个表中的任意一个的数据变更都会发送到 Kafka ,前提是多个表的 Schema 信息必须是相同的。
例如,以下订阅任务中,就指定了同一个库下的多张表:

创建 Oceanus SQL 作业
创建 SQL 作业
目前 tdsql-subscribe-connector 仅支持在 SQL 作业中使用,JAR 作业暂时不支持;
在 流计算 Oceanus 控制台 [4] 的作业管理 > 新建作业中新建 SQL 作业,选择在新建的集群中新建作业。然后在作业的开发调试 > 作业参数中添加必要的 connector,tdsql-subscribe-connector 目前需要手动上传到依赖管理中,然后在作业参数里引用该 JAR 包,Connector 的 JAR 包文件可以联系腾讯云 Oceanus 团队获取;

创建 Source 端
CREATE TABLE `DataInput` ( `id` INT, `name` VARCHAR) WITH ( 'connector' = 'tdsql-subscribe', -- 注意选择对应的内置 Connector 'topic' = 'topic-subs-xxx-tdsqlshard-xxx', -- 替换为订阅任务消费的 Topic 'scan.startup.mode' = 'latest-offset', -- 可以是 latest-offset / earliest-offset / specific-offsets / group-offsets 的任何一种 'properties.bootstrap.servers' = 'guangzhou-kafka-2.cdb-dts.tencentcs.com.cn:321', -- 替换为您的订阅任务 Kafka 连接地址 'properties.group.id' = 'consumer-grp-subs-xxx-group_2', 'format' = 'protobuf', -- 只能是protobuf格式 'properties.security.protocol'='SASL_PLAINTEXT', -- 认证协议 'properties.sasl.mechanism'='SCRAM-SHA-512', -- 认证方式 'properties.sasl.jaas.config'='org.apache.kafka.common.security.scram.ScramLoginModule required username="xxx" password="xxx!";' --用户名和密码);正常情况下,以上的 Source 端参数,除了字段定义外,WITH 参数中需要根据具体订阅任务填写;这里列出 Source 端的相关配置项在订阅任务的具体位置:
- topic [数据订阅] > [查看订阅详情] > [订阅信息]
- properties.bootstrap.servers [数据订阅] > [查看订阅详情] > [订阅信息]
- properties.group.id [数据订阅] > [查看订阅详情] > [消费管理]
- properties.sasl.jaas.config 只需要替换 username 和 password [数据订阅] > [查看订阅详情] > [消费管理]
创建 Sink 端
-- Logger Sink 可以将输出数据打印到 TaskManager 的日志中 -- 程序包下载地址:https://github.com/tencentyun/flink-hello-world/releases -- 需要先在【程序包管理】中上传该程序包,然后在【作业参数】中引用它 -- 参见 https://cloud.tencent.com/document/product/849/58713CREATE TABLE logger_sink_table ( id INT PRIMARY KEY NOT ENFORCED, name STRING) WITH ( 'connector' = 'logger', 'print-identifier' = 'DebugData');为了验证方便,这里 Sink 端采用了 Logger ,可以把数据打印到日志文件中,在使用 Logger Connector 前,同样需要下载相关的 JAR ,上传到依赖管理,然后在作业参数中引用;
同时,为了更好地验证日志中数据打印情况,推荐使用 CLS ,可以更方便地在作业控制台查看作业运行日志;

算子操作
INSERT INTO logger_sink_table SELECT * FROM DataInput;最后,把 Source 端数据插入到 Sink 端;
结果验证
完成 SQL 作业开发后,发布草稿 > 运行作业 ,然后可以在 Source 表中修改或者新增一些数据:
UPDATE `source_table11` SET `name`='test' WHERE `id`=300001;INSERT INTO `source_table11` (`id`, `name`) VALUES (6000000, 'test');DELETE FROM source_table11 WHERE id = 6000000观察 taskmanager 的日志,可以看到 logger 打印出对应的 RowData 信息:
DebugData-toString: +U(300001,test)DebugData-toString: +I(6000000,test)DebugData-toString: -D(6000000,test)注意事项
- TDSQL-MySQL 和 Oceanus 的 VPC 需要连通或者使用同一 VPC;
- 使用 tdsql-subscribe-connector 前,需要构建数据订阅任务;
- tdsql-subscribe-connector 目前只支持增量阶段,没有全量阶段;
- 当订阅任务指定了多个表时,多个表的 Schema 需要保持一致;
参考链接
[1] tdsql-subscribe-connector: https://cloud.tencent.com/document/product/849/71448
[2] 订阅任务:https://cloud.tencent.com/document/product/571/68060
[3] 数据传输服务 TDSQL MySQL 数据订阅: https://cloud.tencent.com/document/product/571/68060
[4] 流计算 Oceanus 控制台: https://console.cloud.tencent.com/oceanus
[5] Logger: https://cloud.tencent.com/document/product/849/58713

点击文末「阅读原文」,了解腾讯云流计算 Oceanus 更多信息~
腾讯云大数据

长按二维码 关注我们